[kafka] 카프카 고가용성과 리플리케이션(장애 극복 방법)
2021.04.30 - [프로그래밍 노트/인프라] - [kafka] 카프카 특징 (데이터 모델, 디자인 특징)
카프카의 고가용성과 리플리케이션
카프카는 높은 가용성을 보장하기 위해 리플리케이션(Replication)기능을 제공한다. (각각의 파티션을 리플리케이션함)
리플리케이션 팩터와 리더, 팔로워의 역할
- 카프카에는 리플리케이션 팩터(Replication Factor)라는 것이 존재하며, 변경은 설정 파일에서 할 수 있다. (server.properties)
- default.replication.factor = 2 (기본값은 1로 설정되어 있음)

- peter 토픽에 대해 리플리케이션 구성한 모습이며, peter 토픽은 브로커1과 브로커2에 위치
- 원본 - 리더 / 복제본 - 팔로워 용어를 사용
- 리더 - 읽기/쓰기 수행
- 팔로워 - 읽기/쓰기를 수행할 수 없으며, 리더의 데이터를 그대로 리플리케이션만함
peter토픽의 리더와 팔로워를 확인하려면 아래의 명령어를 수행
/usr/local/kafka/bin/kafka-topics.sh \
--zookeeper peter-zk001:2181,peter-zk002:2181,peter-zk003:2181/peter-kafka \
--topic peter --describe
Topic:peter PartitionCount:1 ReplicationFactor:2 Configs:
Topic: peter partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2- Leader : 1 → 0번 파티션 리더가 1번 브로커에 존재
- Replicas : 1, 2 → peter토픽이 리플리케이션이 되고 있으며 브로커1, 브로커2에 위치
브로커(리더 파티션)에 장애가 발생한 경우
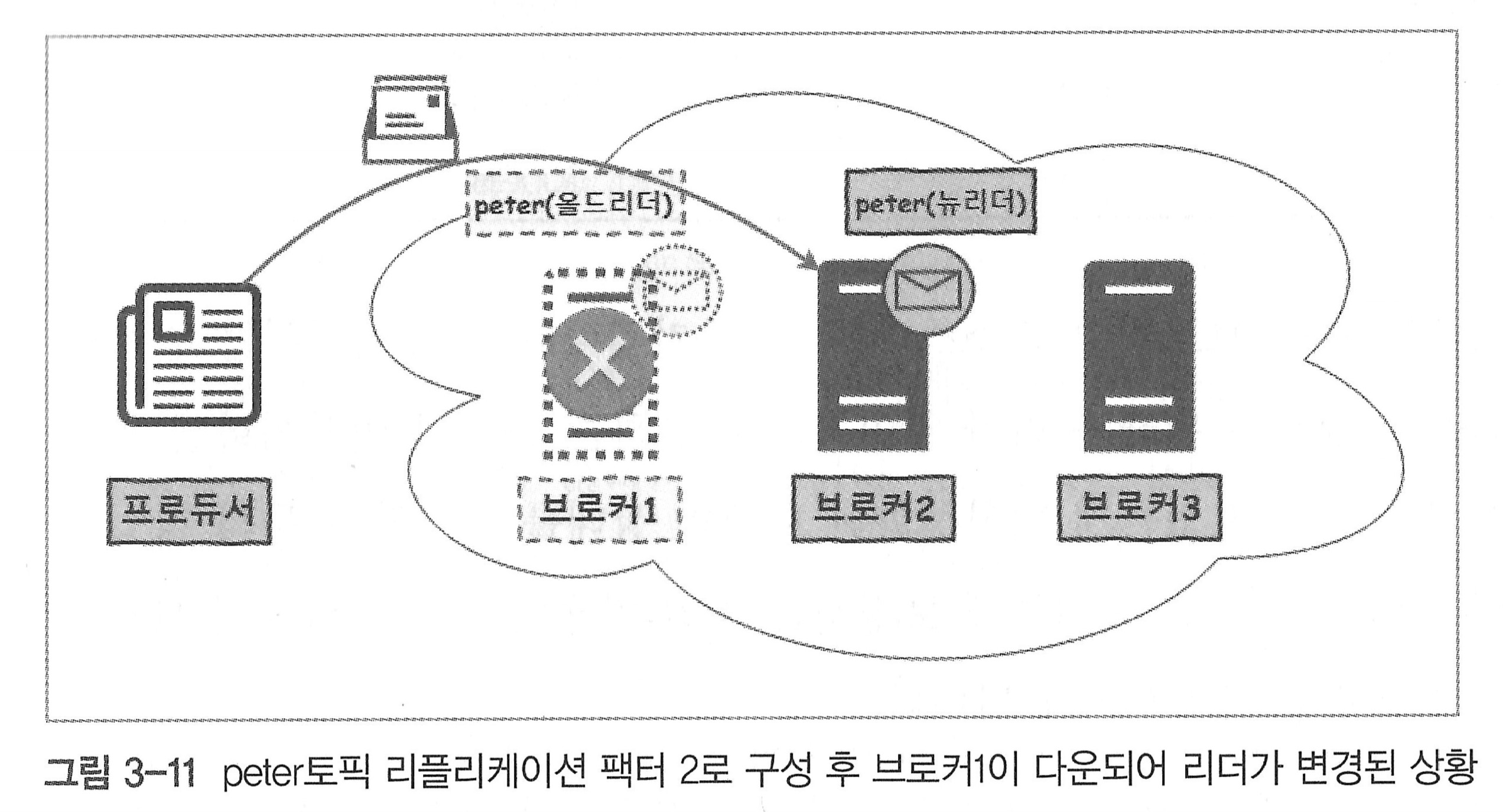
- 브로커2에 남아있는 peter 토픽의 팔로워가 새로운 리더가 되어 프로듀서 요청에 응답하게 됨
- 프로듀서가 메시지를 끊김없이 보낼 수 있는 환경 제공
리플리케이션기능의 단점
- 토픽 사이즈의 n배 크기 저장소가 필요
- 토픽 사이즈가 100GB라고 가정
- 리플리케이션 팩터 : 1 - 카프카 클러스터 내 필요 저장소 크기(100GB)
- 리플리케이션 팩터 : 2 - 카프카 클로스터 내 필요 저장소 크기(200GB)
- 리플리케이션 팩터 : 3 - 카프카 클러스터 내 필요 저장소 크기(300GB)
- 토픽 사이즈가 100GB라고 가정
- 브로커의 리소스 사용량 증가
- 비활성화된 토픽의 상태 체크를 하는 등의 작업이 이루어짐
즉, 모든 토픽에 리플리케이션 팩터 3을 적용하여 운영하기보다는, 해당 토픽에 저장되는 데이터의 중요도에 따라 리플리케이션 팩터를 2 또는 3으로 설정해 운영하는 것이 효율적임
리더와 팔로워의 관리
- 리더 - 모든 데이터의 읽기/쓰기에 대한 요청에 응답하며 데이터 저장
- 팔로워 - 리더를 주기적으로 보면서 자신에게 없는 데이터를 리더로부터 주기적으로 가져옴
만약, 리더로부터 데이터를 가져오지 못하면서 정합성이 맞지 않는 경우가 발생한다면 ? 리더가 다운되는 경우 팔로워가 새로운 리더로 승격되어야 하는데, 일치하지 않기때문에 문제가 발생할 수 있음
ISR(In Sync Replica)
- 데이터 불일치 방지를 위한 개념
- 현재 리플리케이션되고 있는 리플리케이션 그룹을 뜻함
- ISR에 속해 있는 구성원만이 리더의 자격을 가질 수 있음
- 즉, ISR이라는 그룹을 만들어 리플리케이션의 신뢰성을 높이는 것

- 프로듀서가 A 메시지를 토픽을 리더에게 전송
- 리더가 A 메시지를 받고 저장. 팔로워들은 매우 짧은 주기로 리더에 새로운 메시지가 저장됬는지 확인. 팔로워1은 잘 동작하지만, 팔로워2는 잘 동작하지 않음. 리더는 팔로워들이 주기적으로 데이터를 확인하는지 확인하는데 설정된 일정 주기(replica.lag.time.max.ms)가 넘어가면 팔로워는 더 이상 리더 역할을 대신할 수 없다고 판단해 ISR 그룹에서 팔로워를 추방 시킴(추방과 동시에 리더 자격도 박탈)
- ISR 그룹 구성원 2로 축소. 팔로워1은 컨슈머가 메시지를 가져가는 방법(pull)처럼 리더 메시지를 가져와 저장
리더에게 문제가 생기면, ISR 구성원인 팔로워1이 리더라 승격되고, 프로듀서/컨슈머가 요청들을 이어서 처리
모든 브로커가 다운된다면
카프카 클러스터 내 브로커 1대 정도의 물리적 장애나 이슈는 서비스에 치명적인 영향을 주지 않는다는 사실을 알게되었다. 그렇다면 최악의 경우, 모든 브로커가 다운되는 경우 어떻게 대응을 해야할까??

선택할 수 있는 두가지 방법
- 마지막 리더가 살아나기를 기다린다.
- 장점 : 살아난다면 메시지 손실 없이, 요청들을 처리하면서 서비스를 지속적으로 제공 가능
- 단점 : 재시작시 마지막 리더가 반드시 시작되어야 한다. 라는 조건이 존재하므로 장애복구 시간이 길어질 수 있음
- ISR에서 추방되었지만 먼저 살아나면 자동으로 리더가 된다.
- 단점 : 마지막 리더가 아닌 ISR에서 추방당한 팔로워가 리더가될 경우 메시지 손실이 발생(아래 그림 참조)

두 방법의 장단점이 존재하므로 사용자 선택에 따라 사용 가능
kafka 버전 0.11.0.0 이하 - default 2번 방안 선택(데이터 손실이 발생하더라도 빠르게 서비스 제공)
kafka 버전 0.11.0.0 이후 - default 1번 방안 선택(데이터 손실 없이 사용)
# kafka/config/server.properties
- unclean.leader.election.enable : false // 1번 방안
- unclean.leader.election.enable : true // 2번 방안토픽과 파티션 리플리케이션 구성 예시
| 토픽명 | Peter-Topic01 | Peter-Topic02 |
| 파티션 수 | 2 | 2 |
| 리플리케이션 팩터 | 3 | 2 |
| 카프카 클러스터 | 3 | 3 |

참고) http://ldg.pe.kr/Wiki.jsp?page=Kafkaboot1_ch3_kafkadesign