
자바 8의 함수형을 이용하면 가독성 있는 한 줄의 코드로 그룹화를 구현할 수 있다.
예를 들어 고기를 포함하는 그룹, 생선을 포함하는 그룹, 나머지 그룹으로 메뉴를 그룹화할 수 있다. 팩토리 메서드 Collectors.groupingBy를 이용하자.
Map<Dish.Type, List<Dish>> dishesByType = menu.stream().collect(groupingBy(Dish::getType));
{FISH=[parawns, salmon], OTHER=[french fries, rice, season fruit, pizza], MEAT=[pork, beef, chicken]}Dish.Type과 일치하는 모든 요리를 추출하는 함수를 groupingBy 메서드로 전달. 이 함수를 기준으로 스트림이 그룹화되므로 이를 분류 함수(classification function)라고 부른다.
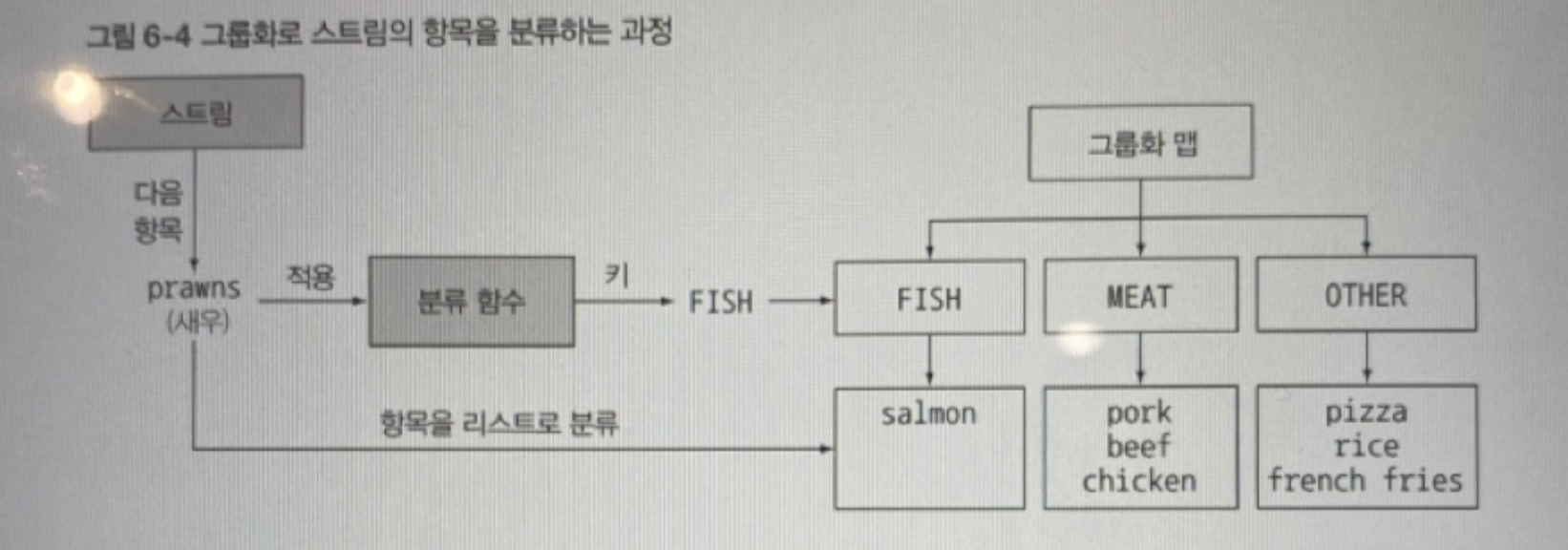
그룹화로 스트림의 항목을 분류하는 과정
단순히 객체의 필드로 분류하는 것이 아닌 복잡한 분류 기준이 필요한 경우에는 메서드참조를 사용할 수 없기 때문에 다음과 같이 람다 표현식으로 필요한 로직을 구현할 수도 있다.
public enum CaloricLevel { DIET, NORMAL, FAT }
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream().collect(
groupingBy(dish -> {
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
}
else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
}
else {
return CaloricLevel.FAT;
}
}));그룹화된 요소 조작
500칼로리가 넘는 요리만 필터링하여 그룹화하고 싶다고 가정하자.
public static final List<Dish> menu = asList(
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("french fries", true, 530, Dish.Type.OTHER),
new Dish("rice", true, 350, Dish.Type.OTHER),
new Dish("season fruit", true, 120, Dish.Type.OTHER),
new Dish("pizza", true, 550, Dish.Type.OTHER),
new Dish("prawns", false, 400, Dish.Type.FISH),
new Dish("salmon", false, 450, Dish.Type.FISH)
);Map<Dish.Type, List<Dish>> caloricDishesByType = menu.stream().filter(dish -> dish.getCalories() > 500).collect(groupingBy(Dish::getType));
{OTHER=[french fries, pizza], MEAT=[pork, beef]}위와 같이 코드를 짤 수 있지만, 문제가 있다. predicate를 만족하는 FISH종류의 요리가 없으므로 결과 맵에서 해당 키 자체가 사라지게 되는 것! 아래 코드를 이용하면 맵으로 그룹핑한다음에 필터링을 수행할 수 있다.
Map<Dish.Type, List<Dish>> caloricDishesByType = menu.stream().collect(
groupingBy(Dish::getType, filtering(dish -> dish.getCalories() > 500, toList())));
{OTHER=[french fries, pizza], MEAT=[pork, beef], FISH=[]}그 외의 groupingBy와 함께 많이 쓰이는 Collector 들을 알아보자.
mapping 활용하기
매핑 함수를 이용해 요소를 변환할 수 있다. 요리이름 목록으로 변환
Map<Dish.Type, List<String>> dishNamesByType =
menu.stream().collect(groupingBy(Dish::getType, mapping(Dish::getName, toList())));flatMapping 활용하기
두 수준의 리스트를 한수준으로 평탄화 작업(flatMap)이 필요할 때 사용. 각 그룹에 수행한 flatMapping 연산 결과를 수집해서 집합(set)으로 그룹화하는 작업
public static final Map<String, List<String>> dishTags = new HashMap<>();
static {
dishTags.put("pork", asList("greasy", "salty"));
dishTags.put("beef", asList("salty", "roasted"));
dishTags.put("chicken", asList("fried", "crisp"));
dishTags.put("french fries", asList("greasy", "fried"));
dishTags.put("rice", asList("light", "natural"));
dishTags.put("season fruit", asList("fresh", "natural"));
dishTags.put("pizza", asList("tasty", "salty"));
dishTags.put("prawns", asList("tasty", "roasted"));
dishTags.put("salmon", asList("delicious", "fresh"));
}
Map<Dish.Type, Set<String>> dishNamesByType =
menu.stream().collect(groupingBy(Dish::getType,
flatMapping(dish -> dishTags.get(dish.getName()).stream(), toSet())));
{MEAT=[salty, greasy, roasted, fried, crisp], OTHER=[salty, greasy, natural, light, tasty, fresh, fried], FISH=[roasted, tasty, fresh, delicious]}다수준 그룹화 - n Depth 구현
두 인수를 받는 팩토리 메서드 Collectors.groupingBy를 이용해서 항목을 다수준으로 그룹화할 수 있다.
바깥쪽 groupingBy 메서드에 스트림의 항목을 분류할 두 번째 기준을 정의하는 내부 groupingBy를 전달해서 두 수준으로 스트림 항목을 그룹화할 수 있음.
Map<Dish.Type, Map<CaloricLevel, List<Dish>>> dishedByTypeAndCaloricLevel =
menu.stream().collect(
groupingBy(Dish::getType, // 첫 번째 수준의 분류 함수
groupingBy((Dish dish) -> { // 두 번째 수준의 분류 함수
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
}
else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
}
else {
return CaloricLevel.FAT;
}
})
)
);
{MEAT={DIET=[chicken], FAT=[pork], NORMAL=[beef]}, OTHER={DIET=[rice, season fruit], NORMAL=[french fries, pizza]}, FISH={DIET=[prawns], NORMAL=[salmon]}}첫 번째 수준의 키 : fish, meat, other
두 번째 수준의 키 : normal, diet, fat
최종적으로 두 수준의 맵은 첫 번째 키와 두 번째 키의 기준에 부합하는 요소 리스트(chichekn, pork ..) 를 값으로 갖는다.
서브그룹으로 데이터 수집
앞에서 두 번째 groupingBy 컬렉터를 외부 컬렉터로 전달해서 다수준 그룹화 연산을 했다. 첫 번째 groupingBy로 넘겨주는 컬렉터의 형식은 제한이 없다. => groupingBy 컬렉터에 두 번째 인수로 counting 컬렉터를 전달해서 메뉴에서 요리의 수를 종류별로 계산할 수 있다.
Map<Dish.Type, Long> typesCount = menu.stream().collect(groupingBy(Dish::getType, counting()));
{MEAT=3, FISH=2, OTHER=4}분류 함수 한 개의 인수를 갖는 groupingBy(f)는 사실 groupingBy(f, toList())의 축약형임
컬렉터 결과를 다른 형식에 적용하기
팩토리 메서드 Collectors.collectingAndThen으로 컬렉터가 반환한 결과를 다른 형식으로 활용할 수 있다.
마지막 그룹화 연산에서 맵의 모든 값을 Optional로 감쌀 필요가 없으므로 Optional을 삭제할 수 있다.
Map<Dish.Type, Optional<Dish>> mostCaloricByType2 =
menu.stream()
.collect(groupingBy(Dish::getType, // 분류 함수
maxBy(comparingInt(Dish::getCalories))));
// {OTHER=Optional[pizza], FISH=Optional[salmon], MEAT=Optional[pork]}
// maxBy가 생성하는 컬렉터결과값이 Optional임
/*
public static <T> Collector<T, ?, Optional<T>> maxBy(Comparator<? super T> comparator) {
return reducing(BinaryOperator.maxBy(comparator));
}
*/
Map<Dish.Type, Dish> mostCaloricByType =
menu.stream()
.collect(groupingBy(Dish::getType, // 분류 함수
collectingAndThen(
maxBy(comparingInt(Dish::getCalories)), // 감싸인 컬렉터
Optional::get // 변환 함수
)));
// {OTHER=pizza, FISH=salmon, MEAT=pork}팩터리 메서드 collectingAndThen 는 적용할 컬렉터와 변환 함수를 인수로 받아 다른 컬렉터를 반환한다.
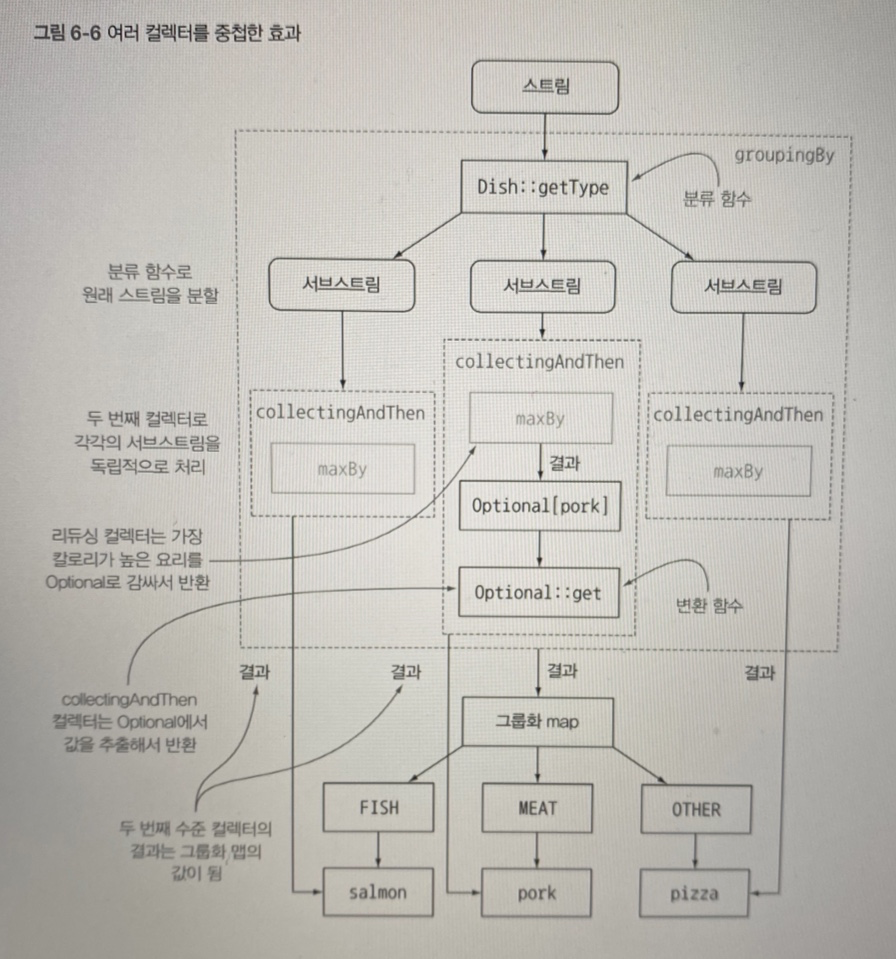
- 컬렉터는 점선으로 표시되어 있으며 groupingBy는 가장 바깥쪽에 위치하면서 요리의 종류에 따라 메뉴 스트림을 세 개의 서브스트림으로 그룹화
- groupingBy 컬렉터는 collectingAndThen 컬렉터를 감싼다. 두 번째 컬렉터(collectingAndThen)는 그룹화된 세 개의 서브스트림에 적용된다.
- collectingAndThen 컬렉터는 세 번째 컬렉터 maxBy를 감싼다.
- 리듀싱 컬렉터가 서브스트림에 연산을 수행한 결과에 collectingAndThen의 Optional::get 변환 함수가 적용된다.
- groupingBy 컬렉터가 반환하는 맵의 분류 키에 대응하는 세 값이 각각의 요리 형식에서 가장 높은 칼로리다.
출처 : 모던자바인액션
'프로그래밍 노트 > JAVA' 카테고리의 다른 글
| [JAVA] 가비지 컬렉터 (Garbage Collector), 두 번째 이야기 (0) | 2024.10.26 |
|---|---|
| [JAVA] Collectors 클래스 정적 팩토리 메서드 (0) | 2021.09.26 |
| [JAVA] Stream Collectors - 1. 리듀싱(reducing) (0) | 2021.09.23 |
| [JAVA]숫자형 스트림 (IntStream, DoubleStream ..) (0) | 2021.09.20 |
| [JAVA]Stream 리듀싱 활용 (0) | 2021.09.20 |